はじめに
NGINXが接続処理に非同期かつイベント駆動のアプローチを用いていることは、よく知られています。つまり(従来型アーキテクチャのサーバのように)、専用プロセスやリクエストごとのスレッドを他に作ることなく、一つのワーカープロセスで複数の接続とリクエストを処理できるということです。これを実現するために、NGINXはソケットをノンブロッキングモードで実行し、epollやkqueueといった効率的なメソッドを用いています。
全負荷のかかるプロセスは少なく(通常1CPUコアごとに1つのみ)一定のため、消費されるメモリは少なく済み、タスク切り替えのためにCPUサイクルが無駄遣いされることもありません。このアプローチのメリットは、NGINXの実例を通してよく知られています。NGINXは、何百万もの同時リクエストやスケールを非常にうまく処理します。

各プロセスが追加メモリを消費する。また、プロセス間の切り替えがCPUサイクルを消費し、Lキャッシュを処分する。
しかし、非同期イベント駆動のアプローチにも問題はあります。問題というより私は「敵」と言いたいところです。そして、その敵の名は、ブロッキングです。残念なことに、サードパーティモジュールの多くはブロッキングコールを用いており、ユーザは(そして時にモジュール開発者たちでさえも)その欠点に気づいていません。ブロッキング処理はNGINXのパフォーマンスを台無しにする可能性があるので、何としても避けなければなりません。
現在の公式NGINXコードでも、全てのケースでブロッキング処理を避けることは不可能です。この問題を解決するために、私たちはNGINXバージョン1.7.11.に、「スレッドプール」という新しい仕組みを導入しました。これが何なのか、そしてどう使用するのかについては後ほどご説明するとして、まずは私たちの敵に向き合ってみましょう。
[編集者注:NGINX Plusユーザの方へ:スレッドプールはNGINX Plus Release 7でサポートされています]
問題
この問題をより良く理解するために、まずはNGINXの仕組みについて少しご説明したいと思います。
原則的には、NGINXはイベントハンドラーであり、接続中に発生するあらゆるイベントについての情報をカーネルから受信し、オペレーティングシステムにコマンドを与えるコントローラです。実際に、オペレーティングシステムがデータを読み込んだり送信したりといったルーチンワークを行っている間、NGINXはオペレーティングシステムの編成によって生じる激務をすべてこなしています。そのため、タイミング良く、かつ迅速に応答することは、NGINXにとって非常に重要となります。

ワーカープロセスがカーネルからのイベントをリッスンし、処理する。
イベントというのは、タイムアウトや、ソケットが読み取り、書き込みの準備ができたという通知、もしくはエラー発生の通知だと思います。NGINXは、まとまったイベント群を受信し、必要なアクションを取りながら一つずつ処理していきます。このようにして、一つのスレッドでキューの単純なループを行い、全ての処理が完了します。NGINXはキューからイベントを取り出し、例えばソケットへの書き込みや読み込みを行うことで対応します。これは通常、非常に素早く行われます(おそらくデータをメモリにコピーするためにいくつかのCPUサイクルを要するだけでしょう)。そして、NGINXは一瞬のうちにキューの全イベントを通過していきます。

全ての処理がひとつのスレッドの単純なループで完了する。
しかし、もし長くて重いオペレーションが発生したらどうなるでしょうか?イベント処理のサイクル全体が、このオペレーションが終わるのを待機し、止まってしまいます。
そのため、私たちが言う「ブロッキングオペレーション」とは、イベント処理サイクルをかなり長い時間止めてしまうオペレーションのことを指しています。オペレーションは様々な理由でブロッキングされます。例えば、NGINXはCPUに負担がかかる長い処理によってビジー状態になることもあれば、リソース(ハードドライブ、ミューテックス、またはデータベースからの応答を同時に得るライブラリの関数呼び出しなど)へのアクセスを待たなければならないこともあります。ここで留意すべきなのは、こうしたオペレーションを処理している間ワーカープロセスは他に何もすることができず、空いているリソースがあったとしても、キューのイベントを処理できないということです。
あるお店に、ある販売員がいたとします。彼の前に長い行列ができています。列の先頭にいる男が、店舗にはないけれど倉庫にはある商品を求め、尋ねてきたとします。その販売員は、その商品を取りに倉庫に行きます。すると、行列全体がその商品を取ってくる数時間もの間待たなければならず、列に並んでいる誰もが不満に思うでしょう。この時の人々の反応を想像できますか?並んでいる人全員の待ち時間が何時間も増えてしまうのに、買いたい商品がこの店に置いていない可能性だってあるのです。

最初の人の注文を、列に並ぶ人全員が待たなければならない。
ほぼ同じことがNGINXでも起こります。メモリにキャッシュされていないファイルを、ディスクから読み込まなければならないときです。ハードドライブは遅いし(特に回転するもの)、キューで待機している他のリクエストはドライブにアクセスする必要がないかもしれないのに、どちらにせよ待たされます。その結果、レイテンシは増えても、システムリソースは十分に活用されません。

たった一つのブロッキングオペレーションが、後続する全てのオペレーションを著しく遅延させることがある。
オペレーティングシステムの中には、ファイルの読み取り・送信用に非同期インターフェイスを提供しているものもあります。NGINXでは、このインターフェイスを使うことができます(aioのディレクティブをご参照ください)。ここで良い例としてFreeBSDが挙げられますが、残念ながらLinuxは良い例とは言えません。Linuxは、ファイル読み取り用の非同期インターフェイスを提供しているものの、それには重大な欠点が2つあります。そのうちの一つは、ファイルのアクセスとバッファへの整列要求ですが、NGINXはこれにうまく対処しています。もう一つの問題のほうが厄介で、非同期インターフェイスが、ファイルディスクリプタにO_DIRECTフラグのセットを要求してくるのです。つまり、ファイルへのアクセスがメモリのキャッシュをバイパスし、ハードディスクの負荷を増やしてしまいます。これでは多くの場合において、最適な選択肢には到底なりえません。
とりわけこの問題を解決するために、NGINX 1.7.11にはスレッドプールが導入されました。スレッドプールは、NGINX Plusにはまだデフォルトで含まれていませんが、スレッドプールが利用可能なNGINX Plus R6を試してみたい方は当社営業担当までお問い合わせください。
さて、それではスレッドプールがどのようなものなのか、そしてその働きについて掘り下げていくとしましょう。
スレッドプール
先ほどの、遠くの倉庫に商品を取りに行った哀れな販売員について話を戻しましょう。でも彼は賢くなり(それか、ひょっとしたら怒った客の群に殴られて賢くなったのかも?)、配送サービスを雇うことにしました。もう誰かに遠くの倉庫にある物を頼まれたとしても、配送サービスに注文をすれば彼らが対処してくれるので、自ら倉庫に取りに行かなくても済みます。その間、この販売員は他の顧客へのサービスを続けられるのです。こうして、探している商品がその店にないという人だけが待っている状態となり、他の人はすぐに買い物を済ますことができるようになりました。

配送サービスに発注することで、行列をなくすことができる。
NGINXに関して言うと、この配送サービスの機能を担っているのがスレッドプールです。スレッドプールは一つのタスクキューと、キューを処理するたくさんのスレッドから成り立っています。ワーカープロセスが時間のかかりそうなオペレーションをする必要があるとき、それ自体がオペレーションを処理する代わりに、プールのキューにタスクを差し込みます。そして、タスクはそのキューから取り出され、空いているスレッドのどれかによって処理されることが可能となります。
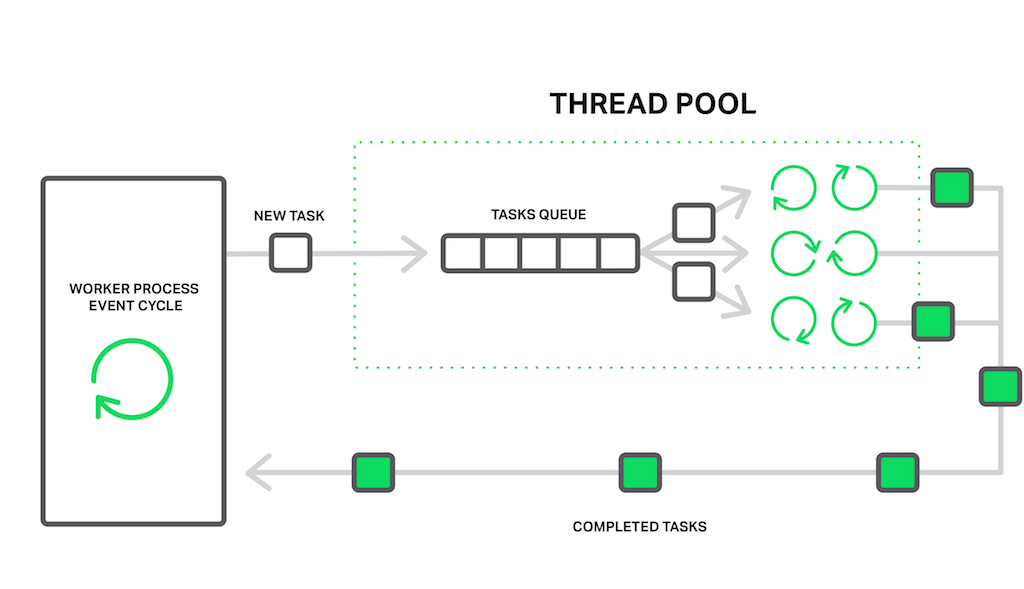
ワーカープロセスがブロッキングオペレーションをスレッドプールにオフロードする。
そうなると、もう一つキューがあるような気がしますね。その通りです。しかし、この場合、このキューはある特定のリソースによって制限されるのです。ドライブがデータを作り出すより早く、ドライブから読み取りを行うことはできません。もはや、少なくともドライブが他のイベントの処理を遅らせることはなくなり、ファイルにアクセスする必要があるリクエストのみが待機する状態となるのです。
「ディスクからの読み取り」オペレーションは、ブロッキングオペレーションの最も一般的な例として使われることが多いのですが、実際NGINXのスレッドプールは、主なワーキングサイクルでの処理に適さない、あらゆるタスクに使うことができます。
現在は、ほとんどのオペレーティングシステムにおけるread() システムコールと、Linuxでのsendfile()という2つの必要不可欠なオペレーションのためだけに、スレッドプールへのオフロードが実装されています。私たちは、実装に関するテストとベンチマークをし続けるつもりです。そして、もし明らかなメリットがあれば、将来的なリリースで他のオペレーションをスレッドプールにオフロードするかもしれません。
ベンチマーキング
それでは、理論から実践へと移りましょう。スレッドプールを利用する効果を実証するために、ブロッキングとノンブロッキングが混ざった最悪のパフォーマンスをシミュレートした総合的なベンチマークを行っていきます。
これには、メモリに乗り切らないことが保証されるデータセットが必要となります。48GBのRAMを搭載したマシンで、4MBファイル郡で256GBのランダムなデータを生成し、NGINX 1.9.0を設定して実行しました。
設定はすごく単純です。
worker_processes 16;
events {
accept_mutex off;
}
http {
include mime.types;
default_type application/octet-stream;
access_log off;
sendfile on;
sendfile_max_chunk 512k;
server {
listen 8000;
location / {
root /storage;
}
}
}ご覧のとおり、パフォーマンスをより良くするために少し調整をしました。loggingとaccept_mutexは無効、sendfileは有効にし、そしてsendfile_max_chunkを設定しました。この最後のディレクティブで、sendfile()コールをブロッキングするのに消費する最大時間を減らすことができます。というのも、NGINXはファイル全体を一度に送信しようとせず、512KBごとに送信するからです。
このマシンはIntel Xeon E5645(12コア、計24HTスレッド)プロセッサ2つと、10Gbpsのネットワークインターフェイスを搭載しています。ディスクサブシステムとして、RAID10アレイに付けた4つのWestern Digital WD1003FBYX ハードドライブを使用します。これらすべてのハードウェアを、Ubuntu 14.04.1 LTS.サーバで稼働させます。

ベンチマーク用のロードジェネレータとNGINXの設定。
クライアントは、スペックが同じマシンを2台使用します。このうち1台のマシンで、wrkがLuaスクリプトを使って負荷を作ります。このスクリプトは、200の同時接続を利用し、ランダムにサーバからファイルをリクエストします。すると、各リクエストはキャッシュミスやディスクからの読み取りブロックになる可能性が高くなります。この負荷をランダム負荷と呼ぶことにしましょう。
2つ目のクライアントマシンでは、wrkのコピーを用意し、50の同時接続を用いて複数回同じファイルにリクエストさせます。このファイルは頻繁にアクセスされるため、常時メモリに残ることになります。通常であれば、NGINXはこうしたリクエストを非常に早く処理しますが、ワーカープロセスが他のリクエストによって阻害されるとパフォーマンスが落ちます。この負荷を定負荷と呼ぶことにしましょう。
ifstatを使いサーバマシンのスループットをモニタすることと、2台目のクライアントマシンからwrkの結果を取得することでパフォーマンスを計測していきます。
さて、スレッドプールなしでの最初の実行は、あまりパッとしない結果です。

ご覧のとおり、この設定ではサーバが全部で約1Gbpsのトラフィックを作り出すことができます。topからの出力で、全てのワーカープロセスがほとんどの時間を出入力のブロッキングに費やしていることが分かります(D:割り込み不可能なスリープ状態となっています)。

この場合、CPUはほとんどの時間使われていないにもかかわらず、スループットはディスクサブシステムにより制限されます。wrkによる結果も非常に低いです。

そして、これはファイルが記憶して行われなければならないことを忘れないでください!レイテンシが極端に大きいのは、全てのワーカープロセスが1台目のクライアントマシンの200本の接続によって発生したランダム負荷に対処しようとドライブからファイルを読み込んでビジー状態となり、たちまち私たちの投げたリクエストに対処できなくなるためです。
さてここで、スレッドプールを使ってみましょう。そのためには、aio threds命令をlocationに追加するだけです。
location / {
root /storage;
aio threads;
}そして、NGINXに設定をリロードさせます。

その後、テストを繰り返します。
スレッドプールなしでは1 Gbps前後だったのに比べ、今度はサーバが9.5 Gbps送り出しています!
恐らくもっと送信することも可能だと思われますが、すでに実用最大ネットワーク容量に達してしまっているため、このテストでは、NGINXはネットワークインターフェイスによって制限されています。ワーカープロセスは、ほとんどの時間をスリープ状態で新しいイベントを待機しているだけです(topではスリープ状態を指すSステータスとなっています)。
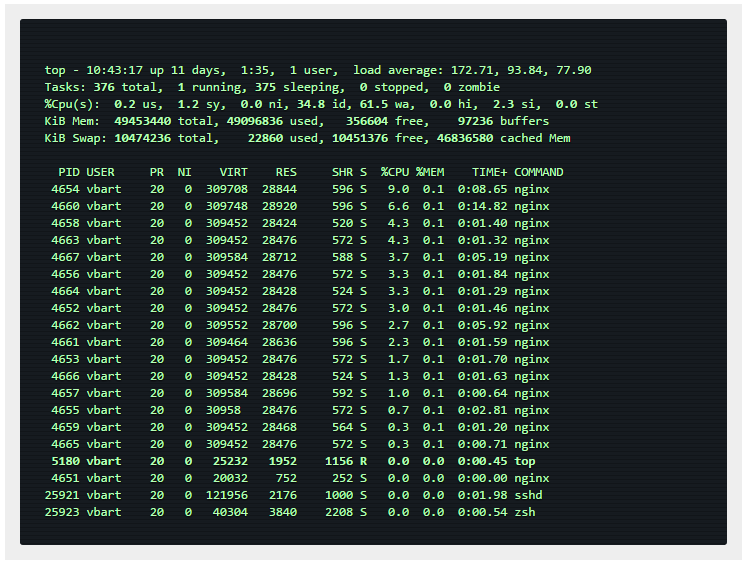
CPUリソースは、まだたくさんあります。
wrkの結果:

4MBのファイルにかける平均時間は7.42秒から226.32ミリ秒(33分の1)に減りました。そして、秒あたりのリクエスト数は31倍(250対8)に増えました!
この理由は、ワーカープロセスが読み取りによってブロックされるものの、リクエストはもうイベントキューで処理を待機せず、空いているスレッドで対処されるためです。ディスクサブシステムが1台目のクライアントからのランダム負荷をできるだけうまく処理している限り、NGINXは残りのCPUリソースとネットワーク容量を使って、2台目のクライアントマシンのリクエストをメモリから処理します。
それでも、魔法の解決策というわけではない
これまでブロッキングオペレーションについて懸念したり、色々と面白い検証をしたりしてきたので、おそらく読者のほとんどが、すでにスレッドプールをサーバに構築しようとしていることでしょう。でも慌てないでください。
事実、幸いにもファイルの読込みと送信オペレーションのほとんどは、遅いハードドライブに対応していません。データセットを格納するRAMが十分あれば、オペレーティングシステムはいみじくも頻繁に使われるファイルを、いわゆる「ページキャッシュ」にキャッシュします。
ページキャッシュが非常にうまく機能してくれるおかげで、NGINXは一般的なユースケースのほぼ全てにおいて素晴らしいパフォーマンスを発揮することができます。ページキャッシュからの読み込みはとても速いため、このようなオペレーションを誰も「ブロッキング」だなんて呼べないでしょう。一方、スレッドプールへのオフロードではオーバーヘッドすることがあります。
そのため、ある程度のRAMがあって作業用データがそこまで大きくなければ、スレッドプールを使わなくても、NGINXはすでに最適に機能しているでしょう。
スレッドプールに読み取りオペレーションをオフロードするやり方は、非常に特殊なタスクに応用できるテクニックです。これは、頻繁にリクエストされる大量のコンテンツがオペレーティングシステムのVMキャッシュに収まらない場合に最も有効です。例えば、高負荷のNGINXベースのストリーミングメディアサーバに関する状況などがこれに当てはまります。この状況は、私たちのベンチマークでシミュレーション済みです。
読み込みオペレーションのスレッドプールへのオフロードを改善できたら最高だと思います。そうすれば私たちは、必要なファイルデータがメモリにあるかないかを効率的に調べるだけでいいのです。そして、なかった場合のみ、読み取りオペレーションを別のスレッドにオフロードさせます。
あの販売員の例えに戻りますが、現在その販売員は、リクエストされた商品が店舗にあるかどうかを知ることができないため、全ての注文を配送サービスに発注するか、または彼一人で対処するかのどちらかをしなければなりません。
この問題の発端は、オペレーティングシステムにこの機能が欠けているためです。2010年に、この機能をfincore()システムコールとしてLinuxに追加しようと初めて試みましたが、実現することはありませんでした。後に、RWF_NONBLOCKフラグ(詳しくは、LWN.netのNon-blocking buffered file read operationsとAsynchronous buffered read operationsを参照のこと)と新しいpreadv2()システムコールの実装を何度も試みました。これらパッチの行く末は、いまだに分からないままです。ここで悲しいのは、これらのパッチが依然としてカーネルに受け入れられていない主な理由が、絶えず自転車置き場の議論(些細なことほど議論が紛糾する現象)をしているせいだと思えてしまうことです。
一方、FreeBSDユーザは心配する必要は全くありません。FreeBSDには、すでにファイル読み取り用に十分良い非同期インターフェイスがあるので、スレッドプールの代わりにこれを使うべきです。
スレッドプールの設定
さて、本当に自分のユースケースにスレッドプールを使うメリットがあると思いますか?それなら設定に入っていきましょう。
スレッドプールの設定は、とても簡単でフレキシブルです。最初に用意すべきなのは、—with-threads configurationパラメータを使ってコンパイルされたNGINXのバージョン1.7.11かそれ以降のものです。最も単純なケースでは、この設定はとても地味に見えるでしょう。aio threadsディレクティブを適切な個所にインクルードすればいいだけです。
\# in the 'http', 'server', or 'location' context
aio threads;これは、スレッドプールの最小限の設定です。実は、これは次の設定の短いバージョンです。
\# in the 'main' context
thread_pool default threads=32 max_queue=65536;
\# in the 'http', 'server', or 'location' context
aio threads=default;これは、32の作業スレッドを持つdefaultと呼ばれるスレッドプールと、タスク65536個分にあたる、タスクキューの最大長を定義します。タスクキューがオーバーロードした場合、NGINXはリクエストを拒否し、エラーをログに保存します。
thread pool "NAME" queue overflow: N tasks waitingこのエラーは、スレッドが、キューにタスクを追加するのと同じ速さで作業することができない可能性があることを意味しています。最大キューサイズを増やしてみて、それでうまくいかない場合は、そのシステムがあまり多くのリクエストを処理できないと考えられます。
すでにお気づきの通り、thread_poolディレクティブを使えば、スレッドの数、キューの最大長、特定のスレッドプールの名前を設定できます。特定のスレッドプールの名前を設定できるということは、いくつかの独立したスレッドプールを設定し、設定ファイル内の様々な場所で異なる目的に使うことができるということです。
\# in the 'main' context
thread_pool one threads=128 max_queue=0;
thread_pool two threads=32;
http {
server {
location /one {
aio threads=one;
}
location /two {
aio threads=two;
}
}
…
}max_queueパラメータが指定されていなければ、65536の値はデフォルトで使用されます。図のように、max_queueをゼロに設定することが可能です。この場合、スレッドプールはスレッドで設定されている数のタスクしか処理できません。つまり、キューで待機するタスクはないのです。
さて、あなたは3つのハードドライブを搭載したサーバを有していて、このサーバをバックエンドからの全ての応答をキャッシュする≪キャッシュプロキシ≫として機能させたいとしましょう。予測キャッシュデータの量がRAMの許容量をはるかに超えていました。これは実は、あなた個人のCDNキャッシュノードです。もちろん、この場合最も重要なことは、ドライブのパフォーマンスを最大に上げることです。
RAIDアレイを設定するという選択肢もありますが、このアプローチには良い点と悪い点があります。さて、NGINXを使ってできることがもう一つあります。
\# We assume that each of the hard drives is mounted on one of these directories:
\# /mnt/disk1, /mnt/disk2, or /mnt/disk3
\# in the 'main' context
thread_pool pool_1 threads=16;
thread_pool pool_2 threads=16;
thread_pool pool_3 threads=16;
http {
proxy_cache_path /mnt/disk1 levels=1:2 keys_zone=cache_1:256m max_size=1024G
use_temp_path=off;
proxy_cache_path /mnt/disk2 levels=1:2 keys_zone=cache_2:256m max_size=1024G
use_temp_path=off;
proxy_cache_path /mnt/disk3 levels=1:2 keys_zone=cache_3:256m max_size=1024G
use_temp_path=off;
split_clients $request_uri $disk {
33.3% 1;
33.3% 2;
\* 3;
}
server {
…
location / {
proxy_pass http://backend;
proxy_cache_key $request_uri;
proxy_cache cache_$disk;
aio threads=pool_$disk;
sendfile on;
}
}
}この設定では、thread_poolディレクティブが各ディスクに対し専用の独立したスレッドプールを定義し、proxy_cache_pathディレクティブが各ディスクにおける専用の独立したキャッシュを定義します。
このsplit_clientsモジュールは、タスクに合ったキャッシュ間(そして結果的にディスク間)のロードバランシングに使われます。
use_temp_path=offパラメータからproxy_cache_pathまでのディレクティブは、対応するキャッシュデータがある場所と同じディレクトリ内に、一時ファイルを保存するようNGINXに指示します。キャッシュを更新する際、ハードドライブ間の応答データがコピーされることを避けなければなりません。
これらすべてを合わせれば、現在のサブシステムで最大限のパフォーマンスを得ることができます。なぜなら、NGINXが個別のスレッドプールを介し、同時かつ単独で各ドライブとやり取りをするからです。16個の独立したスレッドが、読み取り・送信ファイル専用タスクキューを用いて各ドライブに対処します。
オーダーメイドのアプローチは、きっとあなたのクライアントに適していると思います。ハードドライブも同様です。
この例を見れば、いかに柔軟に、NGINXをあなたのハードウェア専用に合わせることができるかがお分かりかと思います。それはまるで、マシンやデータセットとのやり取りに関する最善の方法を、NGINXに指示しているようなものです。また、ユーザ空間でNGINXを微調整すれば、ソフトウェア、オペレーティングシステム、ハードウェアを最適な状態で連携させることが可能となります。そうすることで、すべてのシステムリソースをできる限り効率的に活用することができるのです。
結論
つまりスレッドプールは、名を馳せた長年の宿敵「ブロッキング」を倒し、NGINXの性能を新しい段階へと押し上げてくれる素晴らしい機能だということです。特に私たちが本当に大量のコンテンツで頭を悩ませている時は尚更です。
そしてスレッドプールの長所はまだあります。前述したように、この最新インターフェイスにより、長いオペレーションやブロッキングオペレーションも、パフォーマンスを落とさずにオフロードできる可能性があります。新モジュールや機能性を多く取り備えたNGINXは、新たな展望を切り開いてくれるのです。人気ライブラリの多くは、依然として非同期ノンブロッキングインターフェイスを提供しておらず、そのせいでこれまでNGINXとは互換性がありませんでした。私たちは、独自ライブラリ用のノンブロッキングプロトタイプを開発することに多くの時間とリソースを割いているかもしれませんが、その努力は常に報われるのでしょうか?今やスレッドプールがあれば、このようなライブラリを比較的簡単に使うことができるだけでなく、前述したモジュールについても、パフォーマンスに影響を与えずに作成することができるのです。
今後もNGINXの活躍にご注目ください。
原文:https://www.nginx.com/blog/thread-pools-boost-performance-9x/(2016-3-23) ※元記事の筆者には直接翻訳の許可を頂いて、翻訳・公開しております。