この記事は、オラクル社MySQL主任プロダクトマネージャ、アンドリュー・モルガン氏からのゲスト投稿である。
このブログ投稿の目的は、インメモリ、リアルタイム、かつ拡張可能なMySQLの高可用バージョンであるMySQL Clusterを紹介することだ。タイトルにある「2億QPS(1秒あたりの問合せ数)」という驚くべき内容について話す前に、それがいかにして達成し得るのかを理解するためにもMySQL Clusterとそのアーキテクチャについての紹介を読んでおいたほうがいいだろう。
MySQL Clusterの紹介
MySQL Clusterは、リアルタイム、インメモリ、かつ拡張可能なACIDに準拠したトランザクションデータベースで、99.999%の可用性とオープンソースの低TCO(総所有コスト)を兼ねそろえている。単一障害点なしの、分散型マルチマスタアーキテクチャを中心に設計されているMySQL Clusterは、SQLとNoSQLのインタフェースを介してアクセスされる激しい作業負荷に対し、読み取り、書き込みができるよう自動シャーディングをすることで、汎用的なハードウェア上で水平にスケーリングする。
MySQL Clusterは、もともとはキャリアグレードの可用性とリアルタイム性能を要求するネットワークアプリケーションのための組み込みデータベースとして設計された。そして、MySQL Clusterは機能セットを急速に強化してきており、そのユースケースはweb、モバイル、店舗やクラウドに展開された企業アプリケーションにまで及ぶ。これには、例えば膨大な量のOLTP(オンライン・トランザクション処理)、リアルタイム分析、eコマース、在庫管理、ショッピングカート、決済処理、トラッキング・フルフィルメント、また、オンラインゲーム、金融取引の不正検出、モバイル決済や少額決済、セッション管理やキャッシング、フィードストリーミング、分析とレコメンデーション、コンテンツ管理および配信、コミュニケーションおよびプレゼンスサービス、購買者やユーザプロファイルの管理やエンタイトルメントが含まれる。
MySQL Clusterのアーキテクチャ
アプリケーションに対して透過的でありつつ、裏にはアプリケーションへサービスを一括で提供する3種類のノードがある。下の図は、6つのノードグループに分かれた12のデータノードから成るMySQL Clusterアーキテクチャの簡易図だ。
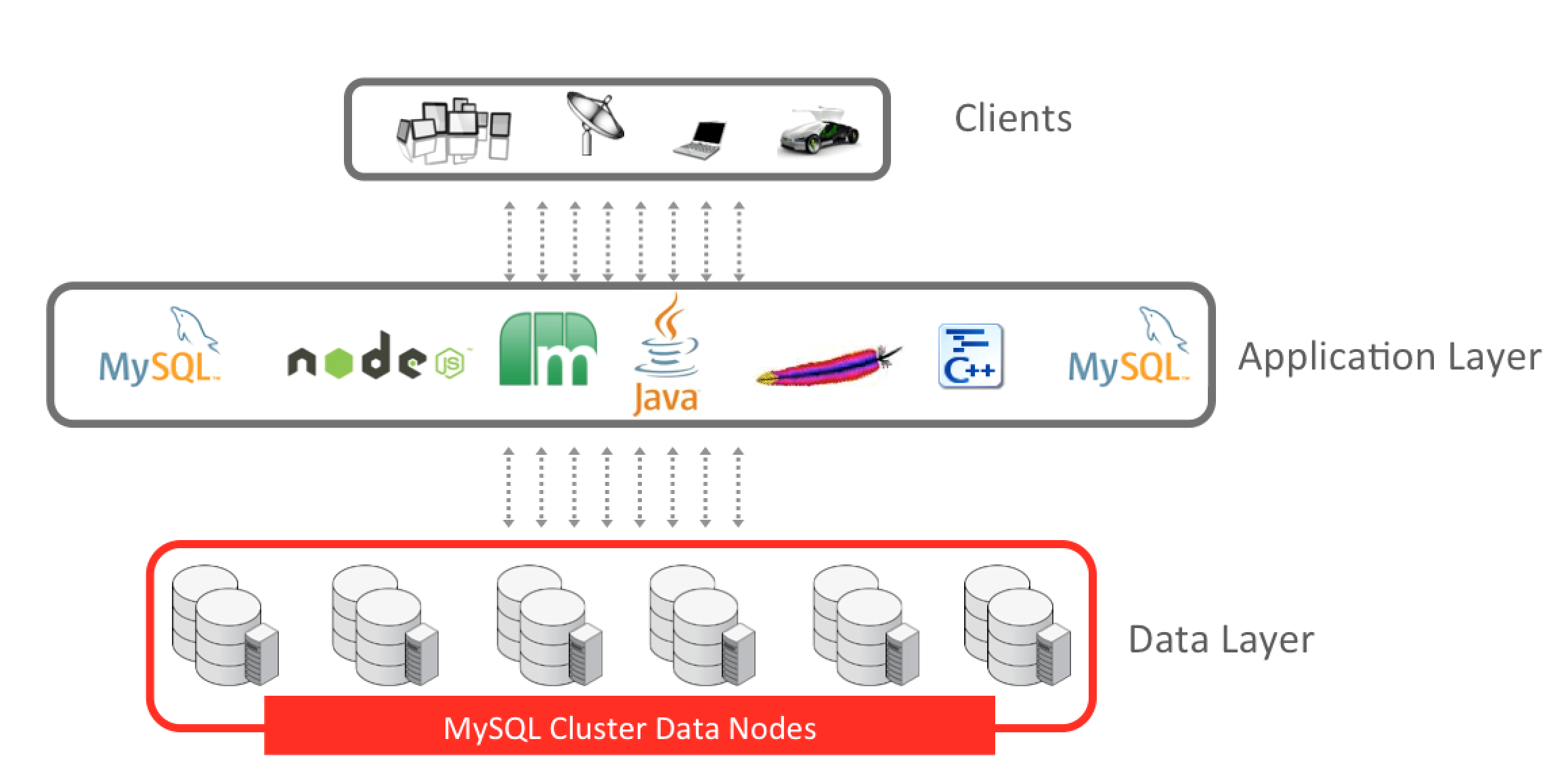 データノードは、MySQL Clusterのメインノードで、次の機能を提供する。インメモリおよびディスクベース・データ両方のストレージと管理、テーブルの自動およびユーザ定義のパーティショニング(シャーディング)、データノード間のデータの同期レプリケーション、トランザクションおよびデータ検索、自動フェイルオーバー、自己回復のための障害後の自動再同期。
データノードは、MySQL Clusterのメインノードで、次の機能を提供する。インメモリおよびディスクベース・データ両方のストレージと管理、テーブルの自動およびユーザ定義のパーティショニング(シャーディング)、データノード間のデータの同期レプリケーション、トランザクションおよびデータ検索、自動フェイルオーバー、自己回復のための障害後の自動再同期。
テーブルはデータノードへ自動でシャーディングされる。そして、アプリケーションの透過性を完璧に保ちながら、データノードはそれぞれがマスタとなって書き込み操作を受け取り、書き込みが集中した商品ノードへの作業負荷を非常に容易にスケールしてくれる。
完全疎結合アーキテクチャにデータを保存・分散し(つまり共有ディスクを使用せずに)、また、データを少なくとも一つの複製(レプリカ)に同期レプリケーションすることにより、データノードに障害が起きても、同じ情報を保存してくれるもう一つのデータノードが常にあるため、リクエストやトランザクションが中断されずに済む。データノード障害に続く短時間(1秒未満)のフェイルオーバー・ウィンドウが出ている間に中断されたどんなトランザクションも、ロールバックして再実行することが可能となる。
データをどのように保存するか、つまり、メモリに全部を保存するか、ディスク(非インデックス・データのみ)にいくつか保存するかを選ぶことが可能だ。インメモリ・ストレージは、頻繁に変更されるデータ(アクティブなワーキングセット)に有用である。停電時など完全なシステム障害の際にMySQL Clusterが回復できるよう、インメモリに保存されたデータには、定期的にローカルの被参照ディスクにチェックポイントが設置され、全てのデータノードが調整される。ディスクベース・データは、空いているRAMよりデータセットのほうが大きい場合など、厳密さを必要とする性能要件を伴わないデータの保存に用いられる。大抵のデータベース・サーバと同様、パフォーマンス向上のため、データノード・メモリ内でよく使われるディスクベース・データをキャッシュするのにページキャッシュが用いられる。
アプリケーションノードは、アプリケーション・ロジックからデータノードまでの接続性をもたらす。アプリケーションは、MySQL Cluster内に格納されたデータにSQLインタフェースの機能を実行する1つまたは複数のMySQLサーバを介してSQLを使用し、データベースにアクセスすることができる。 MySQLサーバを経由する場合は、標準のMySQLコネクタが任意で用いられるため広範囲の技術からのアクセスが提供されている。また、追加制御、より良いリアルタイム動作、優れたスループットのために、NDB APIと呼ばれる高性能(C ++ベース)インタフェースを使用することができる。 NDB APIは、追加のNoSQLインタフェースが直接クラスタにアクセスできるレイヤを提供することでSQLレイヤを迂回して、低レイテンシを可能にしたり開発における柔軟性を向上させてくれた。既存のインタフェースには、Java、JPA、Memcached、JavaScriptのNode.js、(Apacheモジュールを介した)HTTP / RESTが含まれる。すべてのアプリケーションノードは、すべてのデータノードからデータにアクセスすることができる。アプリケーションが残りのノードを容易に使用することができるため、障害を起こしてもサービスの損失を引き起こすことがない。
マネジメントノードは、クラスタ内の全ノードへクラスタ設定を公開する。マネジメントノードは起動時、ノードがクラスタを結合したいとき、システム再構成がある時などに使われる。マネジメントノードは進行中のデータ実行やアプリケーションノードに影響を及ぼすことなく、停止・再起動されることがある。初期設定では、マネジメントノードはスプリットブレインやネットワーク分割を示すクラスタを引き起こすネットワーク障害のイベント時にアービトレーション・サービスを提供している。
透過性シャーディングを通じた拡張性(スケーラビリティ)の実現
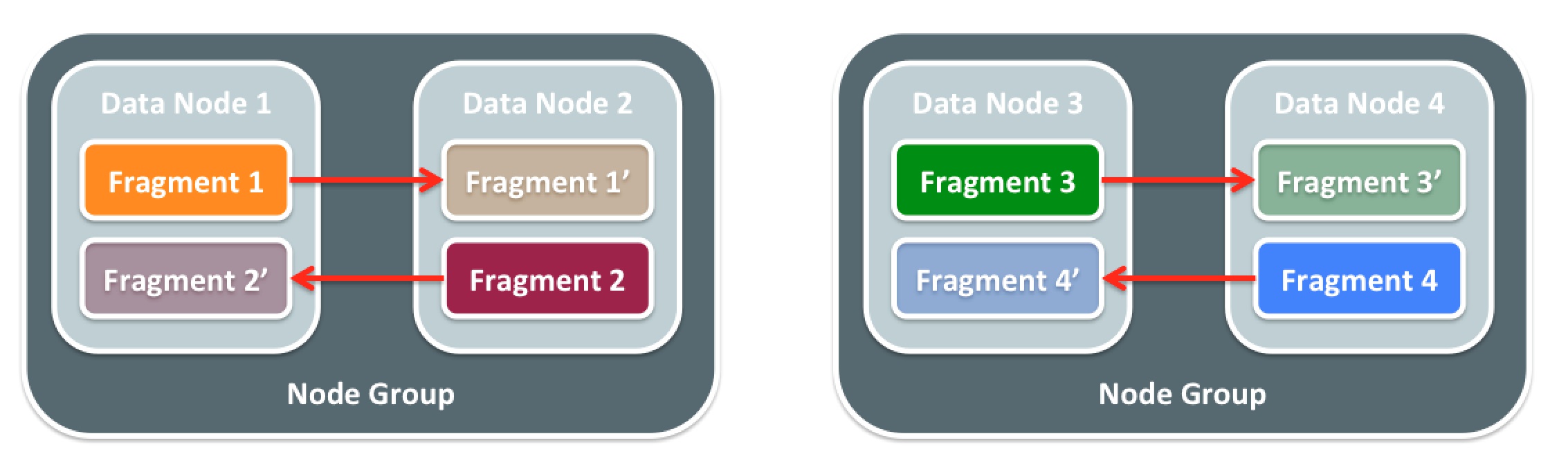 どのテーブルの行も、透過的に、複数のパーティションまたは断片に分割される。各断片にそのデータのすべてを保持し、読み書きを全て処理する単一のデータノードが存在することになる。各データノードはバディを持っていて、それらが一緒になってノードグループを形成する。バディは、それ自身の一時的な断片と、二次的なコピーを保持している。トランザクションがコミットされたときに、変更が両データノード内に確実に格納されることが保証されるよう、同期2相コミットプロトコルが使われる。
どのテーブルの行も、透過的に、複数のパーティションまたは断片に分割される。各断片にそのデータのすべてを保持し、読み書きを全て処理する単一のデータノードが存在することになる。各データノードはバディを持っていて、それらが一緒になってノードグループを形成する。バディは、それ自身の一時的な断片と、二次的なコピーを保持している。トランザクションがコミットされたときに、変更が両データノード内に確実に格納されることが保証されるよう、同期2相コミットプロトコルが使われる。
デフォルトでは、テーブルのプライマリキーがシャードキーとして使用され、MySQL Clusterは、どの断片またはパーティションを格納すべきかを選択するためにそのシャードキーにMD5ハッシュを実行する。トランザクションやクエリが複数のデータノードにアクセスする必要がある場合、データノードの一つがトランザクション・コーディネータとしての役割を担い、リクエストされたその他のデータノードに作業を委任する。そして、その結果はアプリケーションに表示される前に結合される。ここで留意すべきは、複数のシャードやテーブルからのデータを結合するトランザクションやクエリを行うことも可能だということだ。このことは、シャーディングを行う典型的なNoSQLデータストアに比べて、大きな優位性があることに他ならない。

最高の(線形)スケーリングが実現するのは、実行中の高負荷クエリやトランザクションが単一データノードにより満たされるときだ(中間データノードのメッセージング送受信によるネットワークの遅延を減少させるため)。これを実現するには、アプリケーションが分配認識されている必要がある。これが本当に意味するのは、設定(スキーム)を定義している人は、どのカラム(複数可)がシャーディングキーに使われるかをオーバーライドできるということだ。例を挙げてみると、この図はユーザIDとサービス名によって構成された複合プライマリキーの表を示している。つまり、ユーザIDをシャーディングキーとして使うためだけに選ぶことによって、このテーブル内の任意ユーザ用のすべての行が常に同じ断片にあることになる。さらに強力なのは、同じユーザIDカラムが他のテーブルに使われていて、これらがシャーディングキーとして設計されていた場合、全テーブルのすべての任意データは、ユーザを単一データノード内で処理できる同一の断片およびクエリまたはトランザクション内にあるということだ。
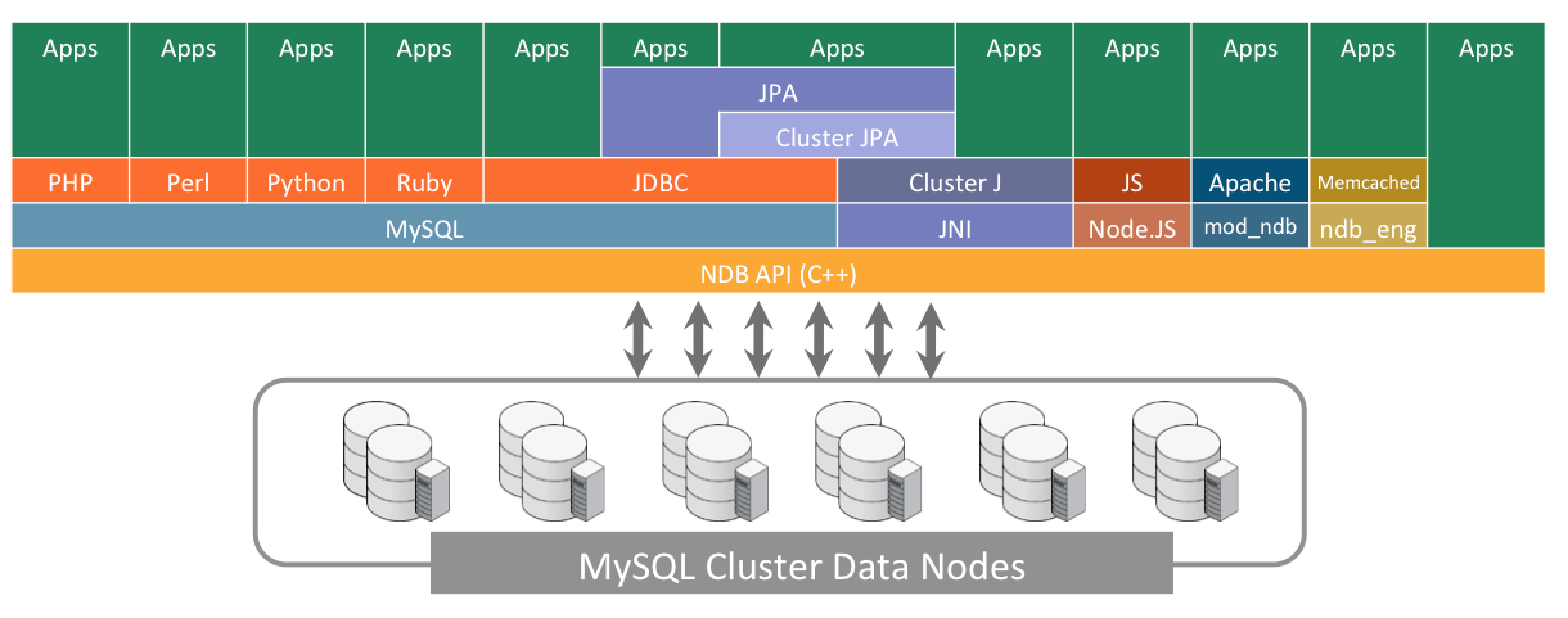
データに最速アクセスするにはNoSQL APIを使用しよう
MySQL Clusterは、格納されたデータにアクセスするためのさまざまな方法を提供している。最も一般的な方法はSQLだが、図に見られる通り、データの読み書きをデータベースから直接させることをアプリケーションに許可するネイティブAPIがたくさんある。そしてそれは、MySQLサーバを通過したりSQLへ変換したりする際の非効率性や開発の複雑さを伴わない。こうしたAPIはC++、Java、JPA、JavaScript/Node.js、http、Memcachedプロトコル用が存在する。

毎秒2億クエリというベンチマーク
MySQL Clusterが処理するように設計されたワークロード(作業負荷)は二種類ある。一つは**OLTP(オンライントランザクション処理)**だ。メモリ最適化されたテーブルは、耐久性がある一方でサブミリ秒の低レイテンシとOLTPワークロードによる極端な並行処理レベルをもたらす。また、これらはディスクベースのテーブルと一緒に用いられる。二つ目は、アドホック検索だ。MySQL Clusterは、非インデックス列で検索を行うときに大幅なスピードアップをもたらし、テーブルスキャン実行時に使用できる並列処理の量を増やした。
そうはいっても、MySQL ClusterはOLTPワークロードにおいて、特に大量のクエリやトランザクションが並行して送信された時に、最高の能力を発揮する。そこで、より多くのデータノードがクラスタに追加されるにつれて、NoSQLがどれ程拡張するかを測るため、flexAsynchベンチマークが使われてきた。
このベンチマークは、専用の56スレッドのインテルE5-2697 v3 (Haswell)マシンで実行中の各データに対して行われた。この図は、データノード数が2から32まで増えている時(注:MySQL Clusterは現在最大48のデータノードに対応している)、いかにスループットがスケールしたかを示している。このように、スケーリングは事実上直線的で、32データノードのところでスループットは毎秒2億のNoSQLクエリに達している。
最新の結果と、テストのより詳細な説明はMySQL Clusterベンチマークページで見ることができる。
これらの2億QPSベンチマークはMySQL Cluster 7.4(現時点で最新のGA版)で実行されたものだ。このリリースについての詳細は、このMySQL Cluster 7.4のブログ記事、またはこのオンラインセミナー再生にてご覧いただきたい。
原文:http://highscalability.com/blog/2015/5/18/how-mysql-is-able-to-scale-to-200-million-qps-mysql-cluster.html(2015-5-18) ※元記事の筆者には直接翻訳の許可を頂いて、翻訳・公開しております。